On contractualism, reasonable compromise, and the source of priority for the worst-off
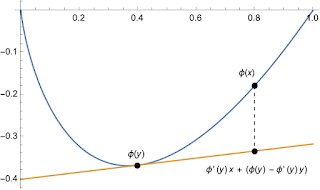
Different policies introduced by a social planner, whether the government of a country or the head of an institution, lead to situations in which different peoples' lives go better or worse. That is, in the jargon of this area, they lead to different distributions of welfare across the individuals they affect. If we allow the unfettered accumulation of private wealth, that will lead to one distribution of welfare across the people in the country where the policy is adopted; if we cap such wealth, tax it progressively, or prohibit it altogether, those policies will lead to different distributions. The question I want to think about in this post is a central question of social choice theory: How should we choose between such policies? Again using the jargon of the area, I want to sketch a particular sort of social contract argument for a version of the prioritarian's answer to this question, and to show that this answer avoids an objection to the standard version of prioritariani